(1) 赛题介绍
本赛题要求参赛队伍根据不同事故类型下的行车环境多模态事故视频理解数据,包括RGB图像、文本信息,交通参与者位置信息,实现在固定事故视频长度条件下(帧率为30,视频时长5s)的交通事故风险预测。
即要求![]() 大于规定的事故风险阈值(通常设置为0.5)的情况下达到最大,即距离事故起始的时间TTA(Time-to-Accident)最大。同时本赛题提供交通参与者的位置信息,可有助于发现事故的风险区域。如图3-1示例:
大于规定的事故风险阈值(通常设置为0.5)的情况下达到最大,即距离事故起始的时间TTA(Time-to-Accident)最大。同时本赛题提供交通参与者的位置信息,可有助于发现事故的风险区域。如图3-1示例:
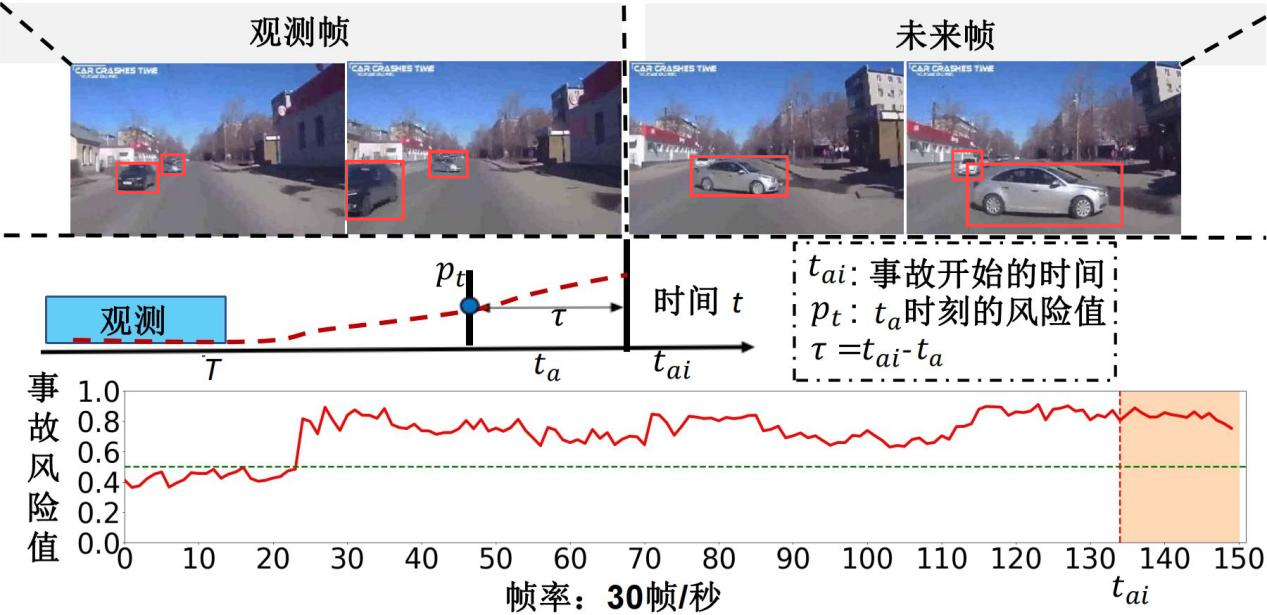
图3-1 5秒事故视频(150帧),自车碰撞其他车辆的事故预测结果、RGB图像、事故时间窗口标注(来源MMAU数据集)

图3-2 部分事故类型数据(来源MMAU数据集)
本赛题包含五类行车道路场景:高速、城市、乡村、山区和隧道道路,考虑多种稀有事故情形:特殊天气(雨天、雪天、雾天)与光照(夜晚)。每个场景中均包含事故时间窗口标注和与事故时间窗口对齐的文本数据。
以下是本赛题任务输入输出的详细介绍。
任务输入:本赛题以不同事故类型视频序列为单位,每个视频下提供
1) 包含事故起始时刻到结束时刻的完整视频帧序列(分辨率:1280×720,以.jpg格式保存);
2) 该视频的基本标注txt文件,包含事故标签(发生事故1/未发生事故0)、事故类型、事故起始时刻(![]() 其中未发生事故的视频
其中未发生事故的视频![]() 标注为-1)、文本信息,用于选手进行开发的数据额外提供交通参与者位置信息的.json文件。
标注为-1)、文本信息,用于选手进行开发的数据额外提供交通参与者位置信息的.json文件。
任务输出:全部用于测试的5s(150帧)事故视频序列的风险预测结果。将每一个测试视频序列的风险预测结果和相应标签存储为字典,如以下方式进行存储:“视频序号”: {“risk”: risk1, risk2, ..., riskT (规定T为150,即根据观测输出150个风险值)], “label”: 1或者0,“![]() ”:
”:![]() 或-1},风险值以ndarray的数组形式进行存储,即字典的键是原始的视频序号,值是预测的风险值、事故标签和事故的开始时刻等标注信息。
或-1},风险值以ndarray的数组形式进行存储,即字典的键是原始的视频序号,值是预测的风险值、事故标签和事故的开始时刻等标注信息。
最后将所有测试结果存储到一个.json文件里进行逐一读取。
文件存储的详细格式请到数据集主页(www.lotvsmmau.net):事故风险预测任务页查看(Task/Vision-based Accident Anticipation)。
本赛题所提供的数据集请到数据集主页下载,在使用数据集前,请您阅读数据集标签页下关于数据集内容的详细说明。
(2) 参赛指南
我们使用分类指标(AP、AUC)、事故预测性能指标(TTA_0.5、STTA_0.5) 指标作为评分标准,评分细则请见下方。
选手应以json文件格式上传结果,细则请见“仿真结果提交”标签页,请选手严格按照格式提交结果,否则无法参加测评!
请您遵守比赛规则,文明参赛!
请在测试结果提交截止时间之前提交您的结果!
(3) 评分标准
评估模型对事故风险估计精确度的指标为AP (Average Precision)、AUC (Area under the Curve of ROC)与事故预测风险性能指标TTA_0.5 (Time to Accident at threshold of 0.5)和STTA_0.5 (Stabilized time to accident at threshold of 0.5)
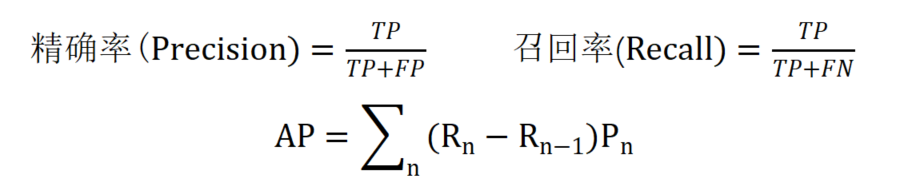
其中正例代表发生事故的测试视频,负例代表未发生事故,正常行驶的视频。TP表示真正例、FP表示假正例、FN表示假负例![]() 分别是第n个阈值的精确率与召回率,AP表示在不同阈值下精确率与召回率的加权平均值。
分别是第n个阈值的精确率与召回率,AP表示在不同阈值下精确率与召回率的加权平均值。

(4) 选手须知
1) 所提交结果应与所提交代码运行结果相符,严禁造假,违者将被取消参与排名资格;
2) 应严格按照格式要求提交结果,格式不符者无法参与结果评测;
3) 请在截止日期前提交您的结果,过期提交将被视为无效!
四、数据集
1. 数据集展示视频
2. 数据集的详细说明:数据集的场景说明、文件夹目录说明、训练集测试集说明等
本届自动驾驶场景交通事故风险预测挑战赛将发布共涵盖58种事故类型的多模态事故理解数据集,数据集包含了五种道路场景与四种天气条件供选手使用。
数据集来自公开的驾驶环境数据集和各种视频流网站,原始视频序列请选手在数据集主页进行下载。应下载的文件共有:原始视频序列压缩包、完整的标签excel文档(包含所有的事故窗口和文本信息标注)、训练和测试txt文件以及每一个视频序列的目标检测数据。
原始视频序列压缩包下载解压后的每一个单位视频文件命名格式应为“事故类型序号/视频序号/images/.jpg”。同时下载解压train.txt和test.txt标签文件。标签文件中每一行存储的数据格式为“事故类型序号、视频序号、事故标签(1/0)、起始视频帧序号、结束视频帧序号、事故起始帧![]() 和视频的事实文本描述”,其中结束视频帧序号和起始视频帧序号的差值始终为150帧。请注意文本信息和交通参与者的位置信息不作强制使用,选手可灵活选择。特别注意,如果在训练中使用了文本信息,则必须将test.txt中的测试序列视频文本置空为“a video frame of {}”以模拟实际环境中文本信息的缺失。
和视频的事实文本描述”,其中结束视频帧序号和起始视频帧序号的差值始终为150帧。请注意文本信息和交通参与者的位置信息不作强制使用,选手可灵活选择。特别注意,如果在训练中使用了文本信息,则必须将test.txt中的测试序列视频文本置空为“a video frame of {}”以模拟实际环境中文本信息的缺失。
选手也可查看完整的excel标签文档,根据训练和测试txt文件中提供的视频名查找到相应的文本信息进行查看,对数据集进行更加全面的了解。
行车环境多模态事故视频理解数据集将于9月15日开放下载,敬请期待!
五、结果提交
请选手们提交以下内容:
1) 提交一个包含详尽的技术路线、预测结果及其说明的技术报告(.pdf文件),文件命名为队伍名_事故风险预测技术报告.pdf
2) 提交一个测评数据集的风险值预测结果,以测评数据集的每个事故视频为一个单位,以.json文件的形式,分别存储每一个测试视频150帧序列的事故风险值,json文件命名为队伍名_accident risk.json,每一个单位测试视频的存储示例如:
#“视频序号”: {“risk”: risk1, risk2, ..., riskT (规定T为150,即根据观测输出150个风险值)], “label”: 1或者0,“![]() ”:
”:![]() 或-1},
或-1},
3) 提交事故风险预测算法代码(包含注释)和对应的ReadMe文件(写清运行代码的需求和步骤)
选手最终提交一个压缩包命名为队伍名_traffic accident.zip,其中包含三个文件夹,分别是技术报告,风险值预测结果,源代码。其中风险值预测结果为存储所有测试视频序列的json文件。
请于测试结果提交截止时间之前提交您的结果,逾期提交将无法参加测评!
IVFC大赛已成功举办了十三届,大赛通过设置各类真实场景,测试和考察无人驾驶车辆的动态驾驶能力,通过建立赛道机制促进国内智能车技术的进步